
老北鼻AI迎来重大更新啦~
无限制,所有用户免费!免费!免费!
本轮测试为全面进入4时代--替代版本3.5做好准备!
? 测试目标:如果测试结果满足预期指标,将全面用4o-mini替代3.5
OpenAI又又又搞事了!
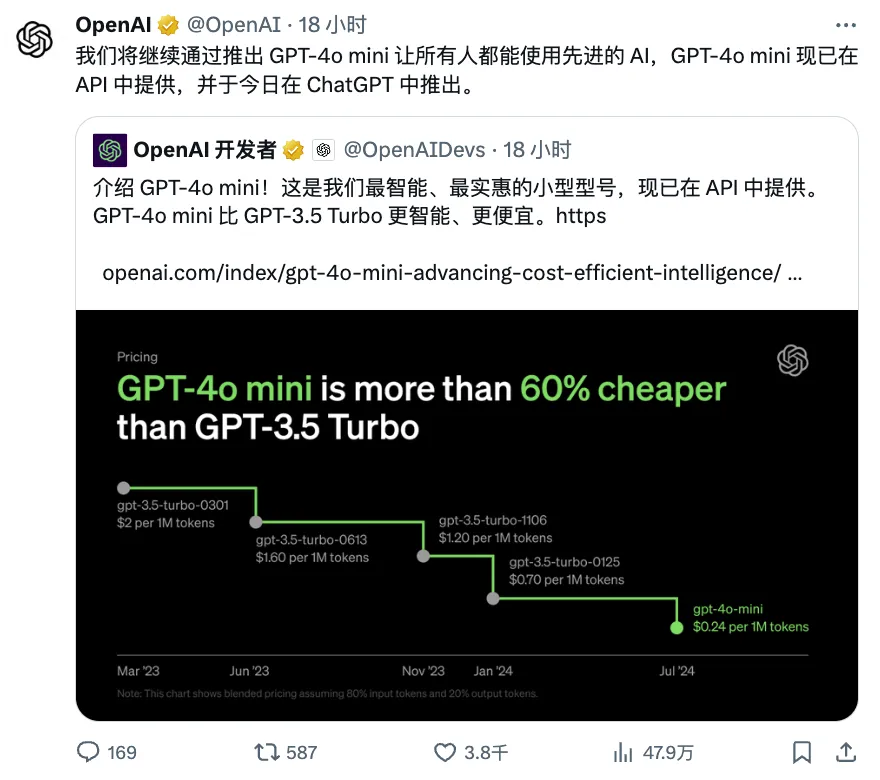
GPT-4o mini直接取代GPT-3.5 Turbo,性能更强。简直是“AI界的经济适用型”,让开发者们使劲拍巴掌?。
不仅文本处理能力强,还能处理多模态任务,小身材大能量。
上下文窗口扩大到128K token,真是硬核升级。
总滴来说,4o mini接棒3.5 Turbo无疑是大福音,AI更普惠的一步,未来可期!
、
OpenAI致力于让智能技术普及大众。今天,我们正式发布了GPT-4o mini,这是我们目前最具成本效益的小型模型。我们相信GPT-4o mini将大幅拓展AI的应用领域,因为它更加经济实惠。GPT-4o mini在MMLU测试中取得了82%的高分,并且在LMSYS排行榜的聊天偏好中优于GPT-4o。其定价为每百万输入标记15美分,每百万输出标记60美分,比之前的先进模型便宜了一个数量级,比GPT-3.5 Turbo便宜超过60%。

GPT-4o mini以其低成本和低延迟支持多种任务,如多个模型调用的链式或并行应用(例如调用多个API)、传递大量上下文给模型(如完整的代码库或对话历史),或通过快速实时文本响应与客户互动(如客户支持聊天机器人)。
目前,GPT-4o mini在API中支持文本和视觉功能,未来将支持文本、图像、视频和音频的输入和输出。该模型拥有128K的上下文窗口,每次请求最多支持16K输出标记,并包含截至2023年10月的知识。借助与GPT-4o共享的改进标记器,处理非英语文本现在更加经济实惠。
具有卓越文本智能和多模态推理的小型模
GPT-4o mini在多个关键基准测试中表现出色
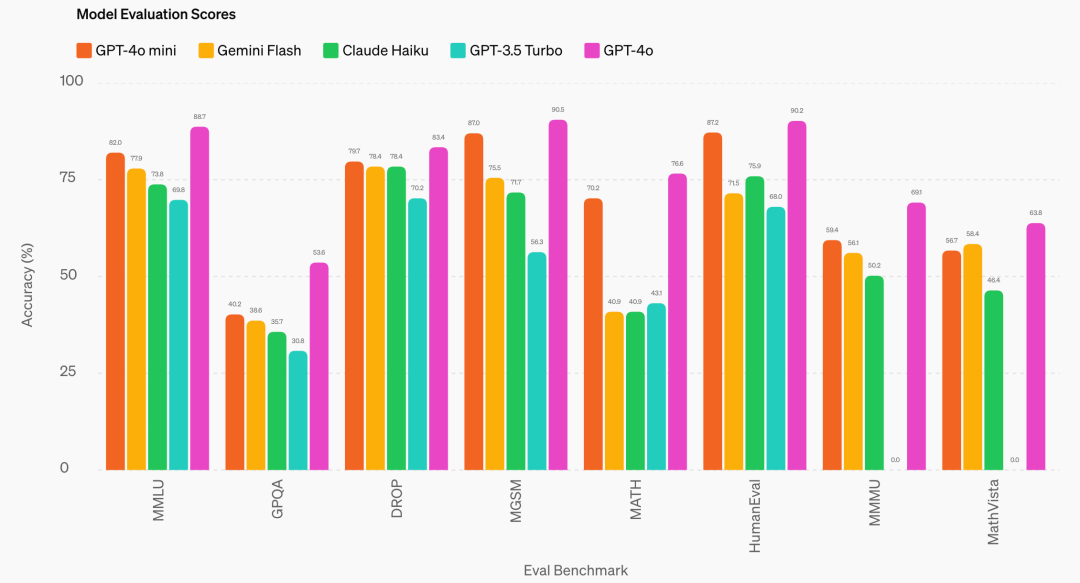
推理任务:GPT-4o mini在涉及文本和视觉的推理任务中优于其他小型模型,在MMLU这个文本智能和推理基准测试中得分82.0%,相比之下,Gemini Flash得分77.9%,Claude Haiku得分73.8%。
数学和编码能力:GPT-4o mini在数学推理和编码任务中表现出色,超越了市场上的其他小型模型。在衡量数学推理的MGSM测试中,GPT-4o mini得分87.0%,而Gemini Flash得分75.5%,Claude Haiku得分71.7%。在衡量编码性能的HumanEval测试中,GPT-4o mini得分87.2%,相比之下,Gemini Flash得分71.5%,Claude Haiku得分75.9%。
多模态推理:GPT-4o mini在多模态推理评估中的表现也很强,在MMMU中得分59.4%,相比之下,Gemini Flash得分56.1%,Claude Haiku得分50.2%。
评估基准
我们与Ramp和Superhuman等公司合作,发现GPT-4o mini在从收据文件中提取结构化数据或生成高质量的邮件响应等任务上表现显著优于GPT-3.5 Turbo。
内置安全措施
基于这些经验,我们的团队还利用研究成果改进了GPT-4o mini的安全性。API中的GPT-4o mini是第一个应用我们指令层次方法的模型,这有助于提高模型抵御越狱、提示注入和系统提示提取的能力。这使得模型的响应更可靠,并有助于在大规模应用中更安全地使用。
我们将继续监控GPT-4o mini的使用情况,并在识别新风险时改进模型的安全性。
可用性和定价
GPT-4o mini现在可作为文本和视觉模型在Assistants API、Chat Completions API和Batch API中使用。开发者每使用100万个输入标记支付15美分,每使用100万个输出标记支付60美分(相当于标准书中约2500页)。我们计划在未来几天内推出GPT-4o mini的微调功能。
在ChatGPT中,免费、Plus和团队用户今天起可以使用GPT-4o mini来替代GPT-3.5。企业用户也将从下周开始访问,以实现我们让AI惠及所有人的使命。
未来展望
在过去几年里,我们见证了AI智能的显著进步,同时成本也大幅降低。例如,GPT-4o mini的每个标记成本自2022年推出的功能较弱的text-davinci-003以来下降了99%。我们承诺继续沿着这一轨迹,降低成本,同时增强模型功能。
我们设想未来,模型将无缝集成到每个应用程序和每个网站中。GPT-4o mini正在为开发者构建和扩展强大的AI应用提供更高效和更经济的途径。AI的未来正变得更加可访问、可靠,并嵌入到我们日常的数字体验中,我们很高兴继续引领这一潮流。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

